사람은 튀고 있는 공을 쫓을 때 이동할 것으로 예상되는 곳으로 움직인다. 예를 들어 움직이던 공이 다른 방향으로 튕겨나가면 사람은 이에 맞춰 실시간으로 적절한 경로를 수정한다. 반면 로봇은 이동하면서 생각하는 대신 계산한 다음에야 행동을 실행에 옮기는 경향이 있다. 사람처럼 실시간으로 경로를 변경하는 데 어려움을 겪을 수 있다는 말이다. 이러한 가운데 구글 브레인(Google Brain)을 비롯해 UC 버클리(UC Berkeley), 엑스 랩(X Lab)으로 구성된 연구팀이 ‘동시 심층강화학습(concurrent Deep Reinforcement Learning)’이라는 알고리즘을 공동 개발했다고 인공지능 및 산업 전문 매체인 '싱크드'가 보도했다. 이 알고리즘은 로봇이 작업이나 동작을 보다 넓고 장기적으로 생각하도록 해주며, 특히 현 작업을 마무리하기 전에 다음 작업을 결정하는 것을 가능케 한다.
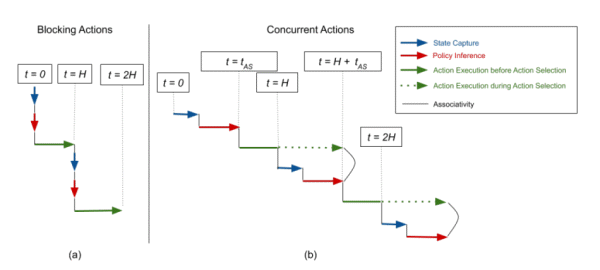
심층강화학습은 제로섬 게임(zero-sum game) 및 로봇 파지(robotic grasping) 등과 같은 시나리오에서 엄청난 성공을 거뒀다. 물론 이 같은 성과는 주로 ‘블록킹 환경(blocking environment)’에서 나타났다. 이 경우에 해당 모델은 '관찰중인 상태'와 '실행중인 작업' 사이의 시간에 '상태 변화'가 없다고 가정한다. 반면 실제 ‘동시 환경(concurrent environment)’에서는 환경 상태가 실시간으로 변할 수 있다. 게다가 에이전트가 초기에 작업을 계산한 후에 환경이 변경되면 순차적인 블록화 방식으로 실행된 작업이 실패할 수도 있다.
이를 해결하기 위해선 로봇이 동시 제어로 작동하도록 해야 한다. 이 경우는 정책에서 작업을 샘플링하는 것이 시간 진화와 동시에 수행돼야 한다.
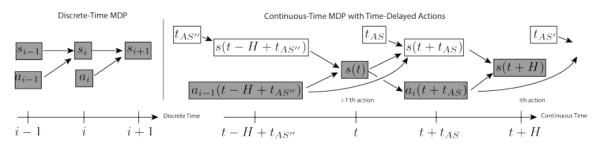
연구팀은 이산 시간(discrete-time) 및 연속 시간(continuous-time) 설정에서 표준 RL 방법을 사용했다. 이어 마르코브 의사결정 프로세스(Markov Decision Processes·MDP)를 동시 동작에 적용했다. 이 경우에 동시 동작 환경은 이전 동작이 여전히 실행되고 있는 동안에도 현재 상태를 캡처한다. 연구팀은 MDP 수정이 동시 작업을 나타내는 데 충분하다고 결론을 내렸다.
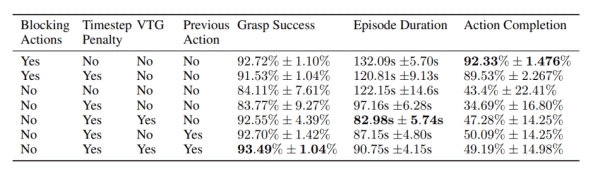
연구팀은 동시 환경에 대처가 가능한 가치 기반(value-based) DRL 알고리즘을 도입해 ‘대규모 로봇 파지 작업 시뮬레이션’과 ‘실제 로봇 파지 작업’ 테스트를 진행했다. 테스트 결과 시뮬레이션 작업에선 이번에 개발한 동시 모델이 ‘블록킹 실행 기준 모델(the blocking execution baseline model)’ 보다 31.3%나 빠르게 작동했다. 또 실제 파지 작업에선 동시 모델이 49%나 빠른 보다 부드러운 트래직터리(trajectory)를 학습했다는 설명이다. | ||||||||||||||||||||||||||||||||||||
| <저작권자 © 로봇신문사 무단전재 및 재배포금지> | ||||||||||||||||||||||||||||||||||||



'인공지능' 카테고리의 다른 글
| '2020 인공지능 온라인 경진대회', 오는 6월 17일부터 개최 (0) | 2020.05.18 |
|---|---|
| "코로나, 음성인식 인공지능 시장 문 활짝 열어" (0) | 2020.05.18 |
| 폭스콘, 비디오 분석 위한 AI프로세싱 시스템 개발한다 (0) | 2020.05.14 |
| 인크루트, 업무 로봇 ‘알리사’ 채용 (0) | 2020.05.12 |
| 제이엘케이, AI 기반 원격의료 시장 진출 (0) | 2020.05.12 |